



On the Internet, our data is the currency we pay for many services. Thanks to huge data sets about our online behavior and preferences, large portals tailor content to our interests, suggest new products for us to buy and draw us into new virtual activities. Knowledge about customers is converted into huge profits. However, not everyone agrees to their data collection and profiling. To help consumers in their clash with online giants, the European Union has introduced new regulations called GDPR - General Data Protection Regulation. One of the elements of the new law is the so-called right to explain. This is the right of every citizen to know the factors that influenced a decision regarding, for example, getting a loan, a particular treatment or obtaining social benefits when those decisions are made with the assistance of algorithms. Machine learning models are a powerful support for knowledge-based decision-making, but they require adequate transparency.
Why do we need explainable models?
With legal solutions at the European Union level, the Panopticon Foundation was able to convince the Polish government and MPs to change the banking law. Every consumer applying for a loan is to have the right to demand from the bank the factors that influenced the assessment of creditworthiness and the decision the bank made. Regulations of this kind make profound sense. The history of machine learning shows that model efficiency is not everything. Models with good efficiency can use factors in prediction that a human would consider unethical or inappropriate or random. One of the more high-profile examples is the case of COMPAS (Correctional Offender Management Profiling for Alternative Sanctions).
In the summer of 2016, a debate heated up over a machine learning-based tool used in courts across the United States. A company called Northpointe (now Equivant) created a system that, based on a variety of factors, predicted the likelihood of whether a convict would commit another crime within two years of leaving prison. COMPAS was intended to simplify the work of judges, make it more objective and help them choose punitive measures accordingly. People with a lower propensity to commit further crimes could leave prison earlier, while offenders with a higher risk of recidivism would remain in prison. The COMPAS model has been used in practice to support judges' decisions and was one example of how machine learning can improve the courts. Until the ProPublica Foundation conducted an extensive study of how it worked and showed that the model's decisions were not fair. It was considered unfair that among prisoners who did not reoffend, the model heavily overestimated the risk for black prisoners, while the risk for white prisoners who became recidivists was underestimated. The model learned racial bias.


This is not an isolated example. Many of the problems with algorithmic data processing can be found in Cathy O'Neil's book Weapons of Mathematical Doom. The book is a critique of the unreflective use of machine learning methods in profiling or risk assessment. Blind faith in machine learning and the intimidation of advanced mathematics results in many poorly built machine learning algorithms that lead to the perpetuation or exacerbation of social inequality. Before writing the book, Cathy O'Neil worked as a data analyst in New York City. Inspired by the dangers she observed, she became involved in so-called model auditing, which is the analysis of the quality and objectivity of decisions made by machine learning algorithms. Many Data Science professionals also recognized this problem, and as a result, many tools began to emerge to evaluate various aspects of machine learning algorithms.
Will the growing number of examples where machine learning models, despite their initial successes, after time began to perform less than randomly cause business to turn away from artificial intelligence once again? Are we in for another AI winter caused by overblown promises of what machine learning models can do? That, of course, no one knows, but what is clear is that in addition to tools to build models, good tools are needed to better understand, monitor and audit them.
Interpretable machine learning
The set of methods for discovering the factors behind the decisions of machine learning models and enlarging the understanding of what the model has learned is called interpretable machine learning (IML) or explainable artificial intelligence (xAI). Many tools can be used to better understand predictive models. Roughly speaking, at least three goals can be distinguished that guide them:
- building transparent/transparent models, often based on knowledge extracted from complex models (black boxes). This is usually done by simultaneously teaching the composite model and explaining or modifying specific algorithms to make them more transparent,
- exploring already learned black boxes to understand how their decisions depend on the input data, and model diagnostics,
- issues related to data privacy, model fairness, and non-discrimination.
Regardless of the purpose, an important distinguishing feature of the methods is whether they are designed for only one type of model (e.g., deep neural networks) or whether they work with any model (we then say they are model-agnostic - model-independent). The model-agnostic approach is particularly important because it allows us to work with complex models (e.g., groups of models that vote together) or automatically created models whose structure we do not know. Two groups of explanations can also be distinguished: local and global. Local methods aim to show which factors (characteristics) influenced a single model decision (e.g., the rejection of a credit application for a particular consumer). This usually involves decomposing the prediction into components related to individual variables.

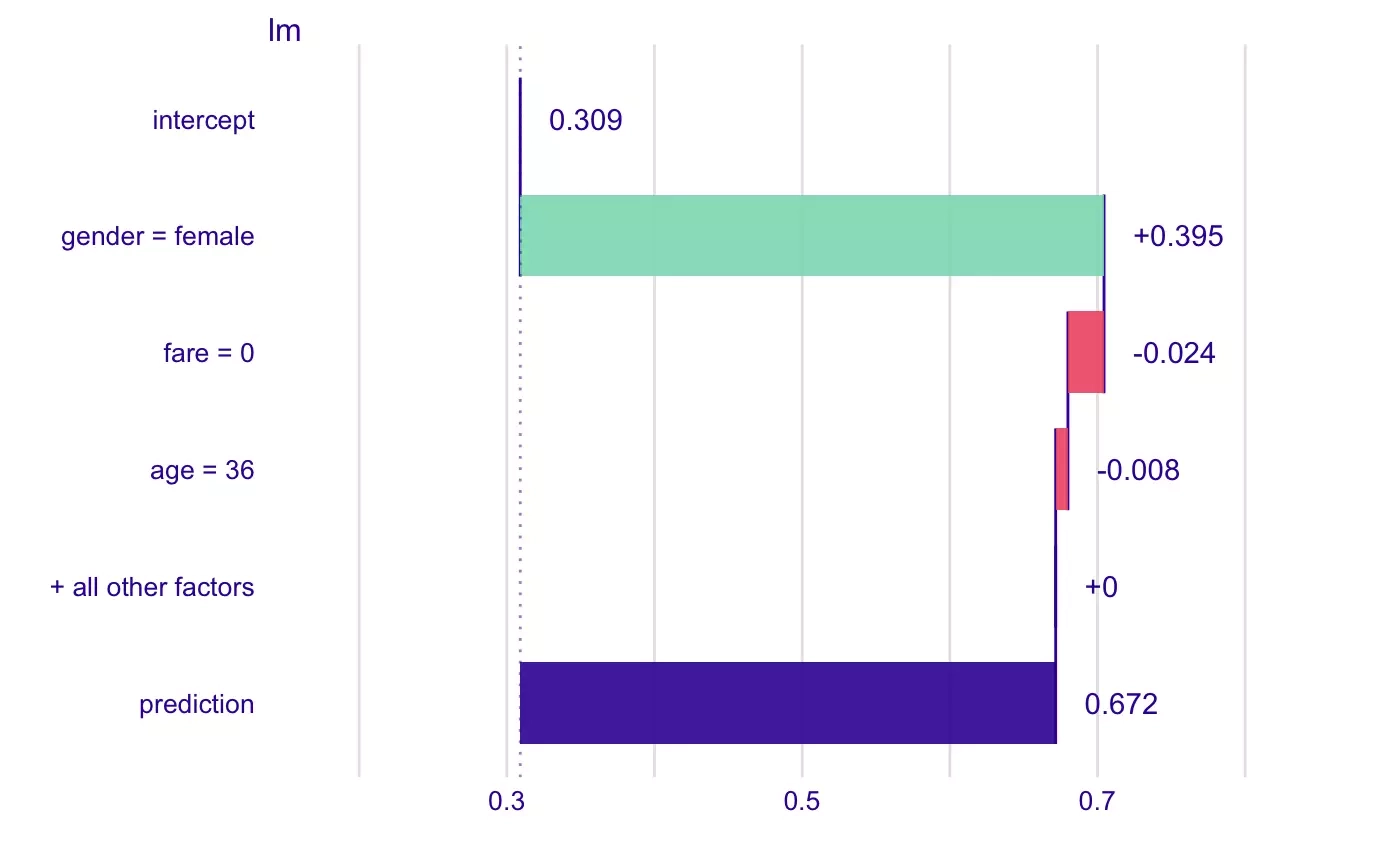
Probability of survival of a Titanic passenger predicted by a linear model. The green and red bars correspond to the contributions of each variable. The contributions add up to the model's prediction value, which corresponds to the purple bar. The chart is from the documentation of the R package iBreakDown.
Global explanations are intended to describe the structure of the entire model. First of all, they describe the validity of the features used by the model and the shape of the relationship between the values of the variables and the model's response. Also included in this category are extended model diagnostics, such as graphs showing model prediction errors.
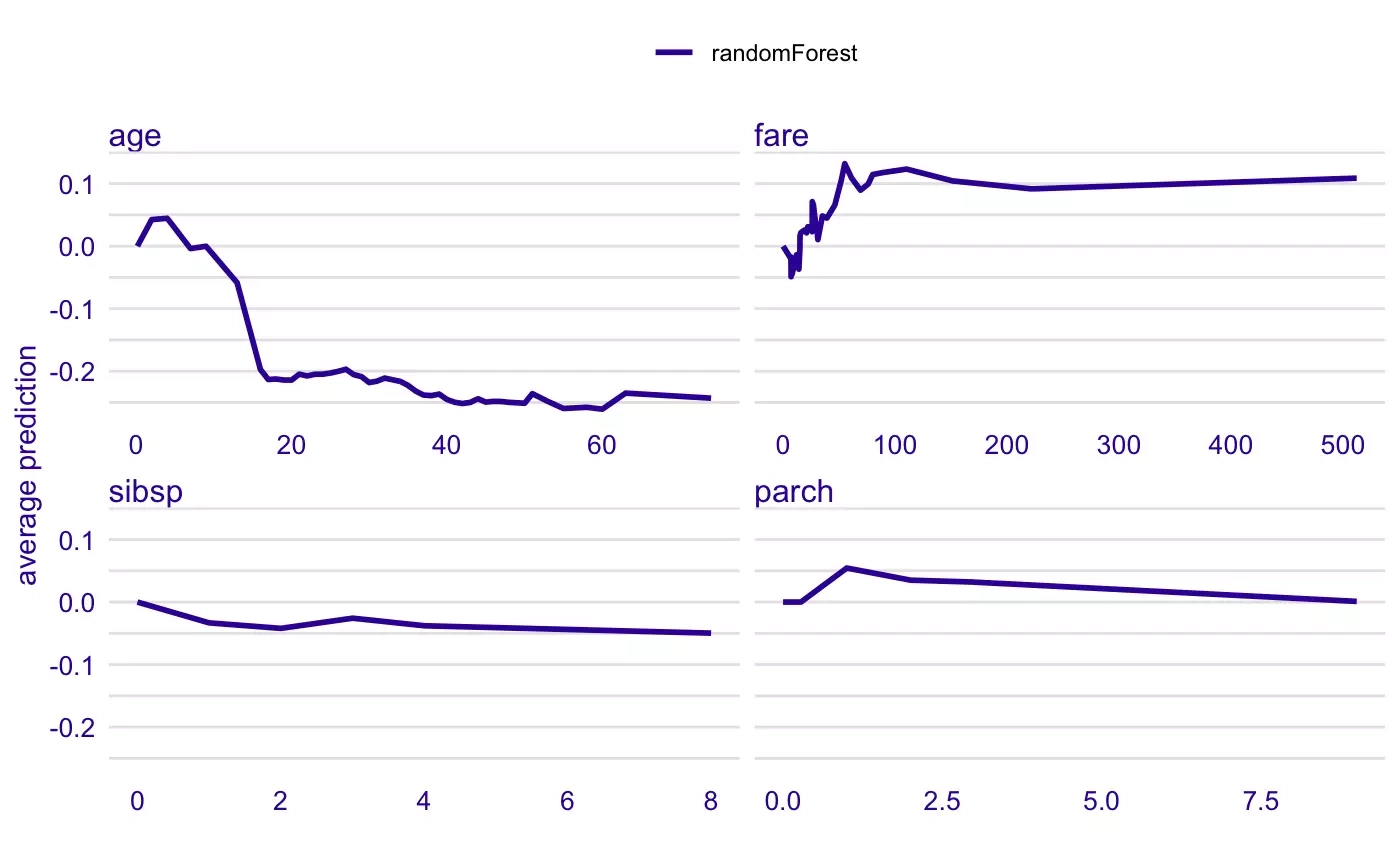
Survival probabilities of a Titanic passenger predicted by a random forest. Boundary dependence plots show how the model's prediction changes with changing values of a single characteristic. The effects of the other variables are averaged. The graphs are from the R ingredients package documentation.
Available solutions
The field of IML is still young and mature solutions for analyzing machine learning models are mainly available for the two most popular programming languages for data analysis, namely R and Python. In Python, you will find some very popular libraries: LIME and SHAP, which implement single instance-level methods for explaining models, and the Skater and ELI5 libraries, which is a collection of different ideas on the explainability of machine learning models. The R language, favored by statisticians and analysts using ML, offers a wide collection of packages for analyzing predictive models, including a universe of DALEX packages based on a unified grammar for explaining predictive models.


Packages in the DALEX family help build and explain predictive models in every phase of their lifecycle, from knowledge extraction for assisted modeling to post-hoc decision explanation of already developed models. The various methods are implemented in accordance with a uniform, universal grammar, so that once the basic concepts are mastered, further exploration of models becomes simple and intuitive. Of the wide range of explainers, some decompose the individual prediction into the factors that had the greatest influence on it, others allow a better assessment of the quality of the model fit, the importance of the variables, or the influence of the selected variable on the model response.
The most popular are model-agnostic methods, i.e. methods that can be used independently of the structure and tool in which the model was created. This independence of explanation from model structure allows the same techniques to be used to explain one model as well as to confront results from different models. This can provide support in model selection or guidance on how to combine models, and it also allows a better understanding of the strengths and weaknesses of competing models. A feature unique to the DALEX package, and very useful in Champion-Challenger analysis, i.e., comparing a currently used model with a new model to improve prediction performance. Another gain of the model agnostic approach is that you can use libraries available in one language, such as R, to explain models built in another language, such as Python, Java, Scala or Julia.
Artificial intelligence is developing and achieving success in many fields such as recommendation systems, natural language processing and image recognition. At the same time, awareness is beginning to form about the impact of algorithms on our lives. Lack of control over the wide-ranging quality of machine learning models can render the results generated by the models useless or even harmful. This is particularly dangerous when socially important decisions are made based on the models, for example, regarding court penalties, access to social benefits or credit. Interpretable machine learning addresses the dangers of uncontrolled use of algorithms. In view of the changing awareness of the described risks and consumer rights, the use of methods to explain algorithmic decisions by companies and institutions processing data is becoming a necessity.



