




From the article you will learn more about Kubernetes (K8s). In short, it is a platform on which business and operational applications are installed. You will learn why, according to the author, K8s is the right solution to serve as, if not a platform, at least its solid foundation. The rest of the article explains why, when installing K8s, it is worth betting on Infrastructure as Code, using the example of a script in Terraform "putting" K8s on Digital Ocean.
In addition, the preparation of an application written in Java and using libraries from the Spring Framework stable for installation on K8s is described. You will also learn more about how to "containerize" Java applications. The examples shown in the article include best practices for configuring some K8s artifacts. The final chapter lists applications that make everyday work with Java, Java@K8s and K8s easier.
Why Kubernetes?
To quote kubernetes.io/en: "Kubernetes, also known as K8s, is an open source software product for automating the process of running, scaling and managing applications in containers." It's not the only product with a similar description, as another example would be OpenShift or Docker Swarm, and if you've ended up here because you need to choose any product from this family, the following arguments are in favor of Kubernetes:
- It is based on the Borg system, which has successfully, for many years, been carrying Google services.
- It has a large and rapidly growing ecosystem.
- Widely available services, support and additional tools.
- A system proven on many productions.
- It is part of the CNCF. It has very rich documentation, even a certain part of it is written in Polish.
**Requirements:**In order to take full advantage of K8s capabilities, an application in a container is required. The developers have made it possible to work only with containers. Do they thus indicate the way applications should be done nowadays? Perhaps that's just the way it is - learn about the main advantages of containers:
- Efficient use of machine resources.
- A container builds quickly and more easily than a VM.
- Consistency of the application on different environments: simplifying - the application works the same way whether it is run during development on a laptop or installed in the cloud.
- Predictable performance, by dedicating resources.
- The application can be run on different operating systems and cloud platforms: Ubuntu, Container Optimized System, Windows, any cloud provider, etc.
What Kubernetes provides:
- Clearly described API + wide product adaptation = large selection of applications, solving operational and business problems.
- Just installing an application on a production is not enough. You need to take care of it - for example, restart it if it has stopped working for some reason, or move it to another machine when the current one "fails".
- Traffic balancing. By running several instances of an application, Kubernetes can balance traffic between them.
- It allows you to work with different storage systems in the same way.
- Application installation, change and rollback is automatic. Using syntax, Kubernetes is described to the expected state, and it takes care of its execution.
- Management of available resources. Once a cluster of machines is provided to Kubernetes, it is tasked with running applications, and in turn Kubernetes takes care of finding the right machine to make the most efficient use of resources.
- It monitors applications and automatically restarts them or replaces them with new ones if they stop working. What's more, it doesn't route traffic to applications if they aren't ready.
- Provides tools for managing confidential information and configuration.
The concept of "Infrastructure as Code"
The concept of Infrastructure as Code (IaC) is not new, but only recently has it become a standard for creating infrastructure and its components. By infrastructure, we mean, for example, creating networks and subnets at a public cloud provider or "putting up" a Kubernetes cluster on virtual machines.
IaC prescribes the creation of infrastructure only as code, in dedicated tools. The tools are characterized by the fact that the code can be run securely many times without risking overwriting or deleting what is already running. Such systems should also allow infrastructure to be put up from scratch.
The unreliable and unsafe solution, although the fastest, is to install components and configure them by clicking or running installers manually. We don't always take notes on what happens during such a startup. Therefore, this is not a good solution. Why else? Here are the reasons:
- It is inefficient in terms of time and therefore financially.
- It is dangerous because we may think the notes are complete. However, due to the fact that they were never repeated from the beginning, some step may be missing. In a situation where, for example, something needs to be installed and still configured, then without using a dedicated tool, it becomes virtually impossible to reliably document the steps.
Using dedicated systems makes it possible to take advantage of the applications and techniques that have been developed around IaC. For example, the Shift Left technique assumes that the cheapest (not just in terms of money) place to catch errors and irregularities in a technical product is during the construction phase. Hence, there is a strong emphasis on testing and analyzing the product as close to the build phase as possible. Examples include:
- Writing unit tests and preventing code changes until the tests cover, for example, 80% of all code.
- Using an analyzer of the libraries used to detect those "with holes" in security.
- Using Snyk, checkov, or Terraform code analysis tools (and more) and pointing out places that are unsafe or incompatible with so-called "best practices." If putting up an infrastructure installs an operating system with a security hole, or creates a publicly accessible S3 resource, these systems report the situation.
Kubernetes vs. Java
Adapting applications, including Java applications, to be installed in production is often contextual, depending on what company and who you work with. No less can be distinguished practices that are recognized by most developers.
Configuration is an independent artifact
Regardless of how the application is built - jar, war, Docker image, configuration in most cases should not be part of the mentioned artifact. The application should look for it on the file system or, for example, query the configuration service. If it is part of the "package", then changing the configuration will trigger the application build process. This means that:
- In development, it unnecessarily prolongs the "develop - release - test" process.
- In mature Continuous Integration projects, the pipeline is elaborate and multi-step, making the process much longer.
- It slows down "hot fixing" and "troubleshooting." Otherwise, you could change the configuration directly on the environment and restart the application (without rebuilding it), which will load the new config.
Below is a sample configuration of a Java application in Spring Framework - /etc/app/application.yaml:
1app: welcome-message: Welcome! management: server.port: 8090
On the other hand, this is the configuration of the logging library - /etc/app/logback.xml
1<?xml version="1.0" encoding="UTF-8"?><configuration scan="true" scanPeriod="30 seconds"> <appender name="stdout" class="ch.qos.logback.core.ConsoleAppender"> <encoder class="net.logstash.logback.encoder.LogstashEncoder"/> </appender> <root level="info"> <appender-ref="stdout"/> </root></configuration>.
When running this application, you need to indicate where these two configuration files are located. This can be done through JVM arguments:
1Java ... -Dspring.config.location=file:/etc/app/ -Dlogback.configurationFile=/etc/app/logback.xml -Dlogback.statusListenerClass=ch.qos.logback.core.status.OnConsoleStatusListener
What if you are installing the application on Kubernetes can be done by the following method:
- A ConfigMap is created with the content from application.yaml, which will later be mounted under the corresponding path in the container:
1kind: ConfigMapiVersion: v1metadata: name: app-configdata: application.yaml: |- app: welcome-message: Welcome! management: server.port: 8090
- Another ConfigMap is created with the contents from logback.xml, which will also be mounted in the container:
1kind: ConfigMapiVersion: v1metadata: name: app-config-logbackdata: logback.xml: |- <?xml version="1.0" encoding="UTF-8"?> <configuration scan="true" scanPeriod="30 seconds"> <appender name="stdout" class="ch.qos.logback.core.ConsoleAppender"> <encoder class="net.logstash.logback.encoder.LogstashEncoder"/> </appender> <root level="info"> <appender-ref="stdout"/> </root> </configuration>.
- Installing the application on Kubernetes, the following configuration files are mounted:
1... spec: ... template: ... spec: ... containers: - name: k8s-java-hello-world livenessProbe: httpGet: path: /health port: 8090 ... volumeMounts: - mountPath: /etc/app/application.yaml name: application-configuration subPath: application.yaml readOnly: true - mountPath: /etc/app/logback.xml name: application-configuration-logback subPath: logback.xml readOnly: true ... env: - name: "JAVA_TOOL_OPTIONS" value: | -Dspring.config.location=file:/etc/app/ ... volumes: - configMap: name: app-config name: application-configuration - configMap: name: app-config-logback name: application-configuration-logback
Share application status
In order for Kubernetes to perform one of its responsibilities, you need to:
- Restart the application if it is not running properly (for example, Spring Context did not get up).
- Don't direct traffic to the application if it's not ready (for example, Spring Context hasn't stood up yet or fails to connect to Kafka).
One option is to add Spring Actuator dependencies:
1<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> <version>${spring-boot.version}</version> </dependency>.
Activation:
1kind: ConfigMap ... data: application.yaml: |- app: welcome-message: Welcome! management: server.port: 8090 health.binders.enabled: true endpoints: web: base-path: / exposure.include: [health] enabled-by-default: false endpoints: health.enabled: true
Indicate the path to the Health Kubernetes resource:
1kind: Deployment ... spec: ... template: ... spec: ... containers: - name: k8s-java-hello-world ... livenessProbe: httpGet: path: /health port: 8090
Time for the application to tell about itself
It is very important to know how the application works - we need to know whether the application "walks", whether traffic is recorded, how long it performs business tasks (e.g. how long it takes to respond to an HTTP request), how many tasks end with errors, what is the CPU and memory usage, what are the GC pauses, etc. Only with this knowledge can you infer the correct UX.
The Spring Actuator library used above instruments many popular frameworks, such as Spring MVC, RestTemplate, Kafka Client and so on. Which means that without doing practically anything, the application informs, for example, about the number of HTTP requests, their execution status how long they lasted. In the case of Kafka, such information as the number of bytes sent, LAG per topic, etc.
1<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> <version>${spring-boot.version}</version> </dependency>.
We still need to decide what tool these metrics will be collected with. Spring Actuator underneath uses Micrometer and its implementation supports the format understood by Prometheus. Kubernetes component applications generate metrics in just this standard. We indicate this standard by adding dependencies:
1<dependency> <groupId>io.micrometer</groupId> <artifactId>micrometer-registry-prometheus</artifactId> <version>${micrometer-registry-prometheus.version}</version> </dependency>.
Next, we activate the endpoint:
1kind: ConfigMap ... data: application.yaml: |- app: welcome-message: Welcome! management: server.port: 8090 health.binders.enabled: true endpoints: web: base-path: / path-mapping.prometheus: metrics exposure.include: [prometheus, health] enabled-by-default: false endpoint: prometheus.enabled: true health.enabled: true server: tomcat: mbeanregistry: enabled: true
After running the application on the local PC, the result of the above steps can be observed by querying the endpoint:
1➜ mvn clean spring-boot:run ➜ curl localhost:8090/health {"status": "UP"}% ➜ curl localhost:8090/metrics -s | grep http tomcat_global_received_bytes_total{name="http-nio-8080",} 0.0 tomcat_connections_current_connections{name="http-nio-8080",} 1.0 tomcat_global_request_max_seconds{name="http-nio-8080",} 0.0 tomcat_connections_keepalive_current_connections{name="http-nio-8080",} 0.0 tomcat_connections_config_max_connections{name="http-nio-8080",} 8192.0 tomcat_threads_busy_threads{name="http-nio-8080",} 0.0 tomcat_global_request_seconds_count{name="http-nio-8080",} 0.0 tomcat_global_request_seconds_sum{name="http-nio-8080",} 0.0
The next step is to install Prometheus and Grafana and observe:

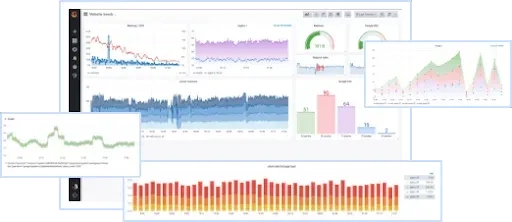
Running web services on different ports
Handling "business" queries is a different issue than metrics. Therefore, it's best to have them available on different ports. This will make it easier for DevOps, for example, who may want to disable authentication if traffic is routed to a metrics port or apply other security rules.
It will also make it easier to configure Istio (the problem of bucketing off /health vs mTLS):
1data: application.yaml: |- management: # Different port for metrics and healthchecks solve problem Istio vs Kubelet server.port: 8090
Following the recommendations - is it worth it?
Kubernetes recommends using generic labs that make up its resources. Considering how many applications, created around the contract and recommendations, are created for Kubernetes. Such an example is Kiali, which can illustrate our system if we stick to Kubernetes recommendations for labels:
1apiVersion: apps/v1 kind: Deployment metadata: name: k8s-java-hello-world labels: # K8s standard label - https://kubernetes.io/docs/concepts/overview/working-with-objects/common-labels/ # Tools around assume such naming convention and build product around it. Ex Istio and Kiali app.kubernetes.io/name: k8s-java-hello-world # K8s standard label - https://kubernetes.io/docs/concepts/overview/working-with-objects/common-labels/ # Tools around assume such naming convention and building product around it. Ex Istio and Kiali app.kubernetes.io/version: 1.0.0 # K8s standard label - https://kubernetes.io/docs/concepts/overview/working-with-objects/common-labels/ # Tools around assume such naming convention and building product around it. Ex Istio and Kiali app.kubernetes.io/part-of: k8s-java-hello-world

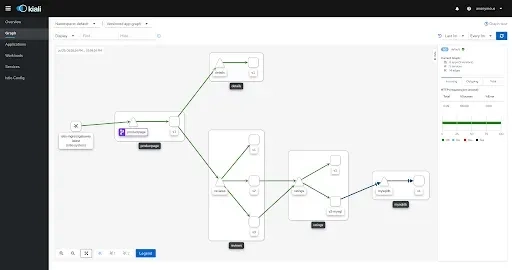
Task-specific permissions rule
This rule applies to any environment - permissions should be minimized to those needed, rather than root/admin from the start. In the case of Kubernetes, set securityContext in spec so that the container is not run from under root:
1spec: securityContext: runAsUser: 1000 runAsGroup: 3000 fsGroup: 2000
Also, make sure that the service itself in Kubernetes uses a different account than the default. This will enable proper configuration of e.g. IaM at the cloud provider, Istio, etc.
1apiVersion: v1 kind: ServiceAccount metadata: name: k8s-java-hello-world
Update libraries
Typically, the application uses Spring MVC library, etc. The owners of the libraries occasionally fix bugs found in them or performance problems. Theoretically, a newer version, is a better product.
To keep your hand in, just activate the plugin in maven or gradle.
1<plugin> <groupId>org.codehaus.mojo</groupId> <artifactId>versions-maven-plugin</artifactId> <version>${versions-maven-plugin.version}</version> <executions> <execution> <phase>verify</phase> <goals> <goal>display-dependency-updates</goal> <goal>display-property-updates</goal> <goal>.display-plugin-updates</goal> <goal>dependency-updates-report</goal> <goal>plugin-updates-report</goal> <goal>property-updates-report</goal> </goals> </execution> </executions> </plugin>.
Verifying libraries for security
OWASP is a recognized IT security organization - it publishes articles on known security holes and suggests how to address them. What's more, it has created and released a plugin that verifies the dependencies used in our application and examines whether they happen to be in the database of libraries(National Vulnerability Database) in which a hole has been detected.
1<plugin> <groupId>org.owasp</groupId> <artifactId>dependency-check-maven</artifactId> <version>${dependency-check-maven.version}</version> <configuration> <failBuildOnCVSS>8</failBuildOnCVSS> </configuration> <executions> <execution> <goals> <goal>check</goal> </goals> </execution> </executions> </plugin>.
Creating a Java application image in a container
Initially, the only way to create application images in a container was to create and populate a Dockerfile and run a Docker application that creates the image according to the commands in the Dockerfile. Creating a "good" image requires knowledge of a couple of technologies:
- Docker - such as the concept of image layers
- Security - what operating system to use, what applications to enable/disable and how to configure them.
Meanwhile, applications have emerged that aggregate this knowledge and create images accordingly:
- JIB from Google. The tool is available as a plugin for Maven and Gradle, and is used to containerize applications inside Google. It does not require the installation of Docker. One of the most important features of the images created by JIB is the "distroless" base image. JIB sticks to the principle that a container in production should have (although it's better to write what it shouldn't have) uninstalled/deactivated applications that don't emphasize business value or aren't required for the operating system to function. This way there will be no bash or sh in the image created this way.
1<plugin> <groupId>pl.project13.maven</groupId> <artifactId>git-commit-id-plugin</artifactId> <version>${git-commit-id-plugin.version}</version> <executions> <execution> <id>get-the-git-infos</id> <goals> <goal>revision</goal>. 2 </goals> <phase>validate</phase> </execution> </executions> <configuration> <dotGitDirectory>${project.basedir}/.git</dotGitDirectory> </configuration> </plugin> <plugin> <groupId>com.google.cloud.tools</groupId> <artifactId>jib-maven-plugin</artifactId> <version>${jib-maven-plugin.version}</version> <configuration> <to> <image> ${container.registry.url}/${container.name}:${git.commit.id.abbrev} </image> </to> <container> <ports> <port>8080</port> </ports> <creationTime>USE_CURRENT_TIMESTAMP</creationTime> <jvmFlags> <jvmFlag>-server</jvmFlag> </jvmFlags> <jvmFlags>.
- Cloud Native Buildpacks (CNB). A specification and its implementation created for the Heroku platform in 2011, and has since gained adaptation from Cloud Foundry, Google App Engine, Gitlab, Knative, Deis, Dokku and Drie. CNB implements best practices for creating OCI images. The tool is available "out of the box" in many CI/CD systems as a step to add to the "pipeline." Download the pack application and use it, for example, as follows:
1export GIT_SHA="eb7c60b" pack build --path . --builder packetobuildpacks/builder:base registry.digitalocean.com/learning/k8s-java-hello-world:${GIT_SHA} --publish base: Pulling from paketobuildpacks/builder ===> ANALYZING Previous image with name "registry.digitalocean.com/learning/k8s-java-hello-world:eb7c60b" not found ===> RESTORING ===> BUILDING *** Images (sha256:dc7bbcc2a5fd3d20d0e506126f7181f57c358e5c9b5842544e6fc1302b934afe): registry.digitalocean.com/learning/k8s-java-hello-world:eb7c60b Adding cache layer 'paketo-buildpacks/bellsoft-liberica:jdk' Adding cache layer 'paketo-buildpacks/maven:application' Adding cache layer 'paketo-buildpacks/maven:cache' Adding cache layer 'paketo-buildpacks/maven:maven' Successfully built image registry.digitalocean.com/learning/k8s-java-hello-world:eb7c60b
Learn more about Kubernetes' capabilities
If you're looking for comprehensive container training, check out our suggestions:
For more training in this category, visit: https://www.sages.pl/szkolenia/kategoria/chmura



