




In this article, I will present in as simple a way as possible what machine learning is all about. When writing, I imagined a reader who is not directly involved in the problem, but needs or would like to know at some general level what the work of the people responsible for building the model is like. Such a person might be, for example, a member of the board of directors, or someone who works on the project in parallel with others, but who is responsible for issues not directly related to building the machine learning model.
I assume that the reader has had at least some exposure to data in electronic form and knows that it can be summarized, for example by counting the average in Excel. Below I give some of the questions I will try to answer in this series. It is definitely not exhaustive, but it is meant to give a general idea of the nature of the articles. Some of these questions are worth asking yourself before you start building the model, others during, for example, when presenting the results.
- How long will it take to build the model? How many people to allocate to it?
- What confidence do I have that the model will work? What are its limitations?
- How good a model are we able to build? Can the current one be improved?
- Basically, what is a , "model"?
- How are we able to predict the future based on historical data?
- What is an error matrix? How to interpret the graphs presented?
- What do the different measures mean: MSE, R2, AUC? How to deduce from them whether the model is good?
Out of necessity, certain aspects will be covered in great simplification. To some questions (for example, about the time it takes to build a model) I will not give any specific answers. Nor will you, the reader, certainly learn how to build a machine learning model yourself. Instead, I hope that you will more or less understand what your team members are doing, and be able to assess whether the model they have created is indeed a good one.


What problems do we apply machine learning to?
Let's start with why machine learning methods are used at all. Let's assume that we are a company that offers loans. We certainly won't give them to everyone, but only to people who have a good chance of paying them back. We would like to quantify this chance (probability). We expect that it depends on certain factors: the customer's financial situation, credit history, family situation, certain character traits. At least some of these factors we are able to measure, if only approximately. As long as we have enough such data and they are indeed related to repayment, then thanks to machine learning methods we will be able to find relationships between them and the probability of loan repayment (that is, build a model).
Another example. We are an insurance company and we need to estimate a person's life expectancy for a valuation. It depends on factors we are able to measure: gender, occupation, medical history. We can build a model that predicts life expectancy based on such information.
In the examples above, the terms , "model" and "machine learning" appeared in very similar contexts. Let's make it clear: our goal is to build a model that, based on certain information, will be able to estimate (predict) other key information. In order to build such a model, we use a certain approach, which we call machine learning.
In what follows, I will call this key information Y (probability of loan repayment, life expectancy), and the information that will be used to estimate it by X (earnings, occupation, gender). Usually, in a particular problem, the information Y is one (has one dimension), while the characteristics of X (so-called predictors) can be very many (many dimensions).
The process of building a model
Let's take a general look at the stages of model building. I will list five, although I will immediately point out that this is my, partly subjective, view. Besides, in specific situations, the whole process may look different: some stages may be practically omitted, others strongly expanded. Importantly, it is usually an iterative process, i.e.: we return to individual stages many times. There are times when, after the "final" validation of the model, the results will be so unsatisfactory that it will be necessary to return to the first stage.
-
A key aspect is the collection of sufficient quantity and quality of data. This is the material from which we build the model (like bricks for a house). What should they be characterized by? Let's assume again that we are a company offering loans. First of all, we need Y information, that is, whether individuals have repaid their loans. If we do not know this, such data can still be useful, but to a very limited extent. Second, we need X information about these individuals, for example, how much they earn, whether they own an apartment outright, whether they have paid off previous obligations. This information should in some way (though perhaps a small one) relate to repayment. In practice, it's best to provide those responsible for building the model with all the information you have about the person - they will determine (using machine learning methods) whether a particular characteristic is useful or not.
-
The next step is to process the data into a form understood by the computer. Most often, this will be in the form of a table with information about individual customers in consecutive rows, as below.

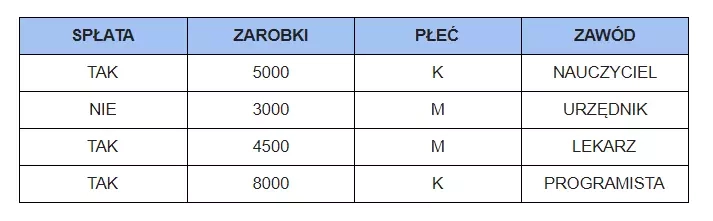
-
Then we try to understand the data, to extract knowledge from them. They tell a story that we want to know, , "interrogating" them. We ask questions and, using the appropriate tools (measures, charts), answer them.
-
Once we understand the data, in particular the relationship between Y and X, we try to describe it with specific mathematical expressions, using appropriate machine learning algorithms. This stage can be called the heart of model building.
-
If the results are satisfactory, we can move on to a summary, for example, in the form of a report or presentation.
What remains is to implement the model, perhaps to create an application - but we won't cover these stages here.
How big should the team be?
Perhaps one person is enough. In principle, all the stages mentioned can be performed by a single employee, and since they are strongly connected, the involvement of more people may not work. However, there are situations in which assembling a team is necessary. There may be so much data and in such a form that we will need a database specialist. Similarly, if the final product is to be an efficient and effective application, we should not expect an analyst to do it. If the model being built is crucial to the company and we can allocate more resources to it, it is a good idea to assign several people (teams) to the project, who will work completely independently and only join forces at the end.
Remember, however, that an analyst working in isolation has little chance of creating a good model. It is imperative that he or she should be able to consult with other company employees who have a good understanding of certain specific aspects of the data: the cost of acquiring the information, access to it when making predictions, legal issues. Many of the patterns that the analyst will see in the data can be explained by employees who don't necessarily know anything about the analysis. They can also be of great help in selecting information that is useful in model building.
Where can you acquire the right skills?
If you are a manager and want to learn a holistic view of the whole issues related to Big Data and Data Science, as well as practical competencies in using them in the management of a department or an enterprise, especially knowledge of the specifics of big data, integration and collection of data from different sources, and architecture of Big Data class solutions, check out the postgraduate program Data Science and Big Data in Management.
During the course of study you will learn to:
- effectively carry out the transformation of an enterprise/department into a data analytics-based enterprise
- effectively lead BigData and Data Science projects
- organize and manage Big Data and Data Science infrastructure
- use the results of data analysis in enterprise management
The study is intended for middle and senior managers performing their functions in the areas of marketing, finance, IT, production chain management, HR, strategic management, among others (but not exclusively).
How long can it take?
The time required to build a model is very difficult to estimate, and largely depends on the specific case. The stage of data collection can be very long (take a year, for example) if we have not done it so far, that is, we have not recorded the information necessary for the model. Usually, however, this data exists, in addition, in electronic form, we just need to obtain it from various departments in the company. If we don't have all the data at the moment, it can be a good idea to construct a model based on what we have at the moment, and then collect additional information, making the next model better.
The stage of transforming the data into a suitable form is usually the most cumbersome and time-consuming. While there are times when they are in the right format right away, this is usually not the case, and it takes quite a bit of proficiency with analytical tools to get through this stage. It is worth adding that if you expect periodic reports from analysts, it is hard to present what you have actually done at this stage.
Understanding the data is a step that some people almost skip, although it is definitely not a good strategy. Models built , "in the dark" can be unstable in practice, and sometimes completely useless (although it's easy to convince yourself and others that everything is fine). Besides, through this stage you can gain a great deal of practical information, not necessarily related to the model itself, which, in addition, can be passed on to others in a relatively simple way in the form of a presentation.
The fourth stage, i.e. describing the sought-after relationship using mathematical formulas, although I have called the heart of model construction, in practice can take the least amount of time. It can be said that this part is largely carried out for us by the computer. The final description of the results need not be time-consuming either, since it should be partly done in the previous stages. On the other hand, it usually takes more than is assumed beforehand. Time also depends strongly on who we are preparing the report for.
Finally, two observations. First, usually the more data, the more time the whole process takes. If you don't have good computer equipment, this can slow down the construction of the model a lot, especially stage four. Second, as I mentioned above, the process of building the model is iterative, we return to each stage many times. Therefore, we can get "some" model (and this is good practice) relatively quickly. In subsequent iterations, the models should get better and better.
The last point is of great importance when we want to plan the total time to build a model. Well, most often there is no such thing as a , "final model", in the sense that we are not able to create anything better. The final model is only the really final one - but if we had an extra month, we would probably be able to get something better (although maybe minimally). One strategy is to aim for a certain preset accuracy, that is, the project continues until that level is reached. Unfortunately, this can cause funding difficulties, or worse, such a level may not be within reach (no matter how much time we allocate).



