




I ended the article "What is a machine learning model?" by saying that testing various machine learning algorithms is simply applying them and seeing how they work. This may seem trivial, but it's not at all, and we'll pause longer on this sentence. Moreover, this approach in a way distinguishes machine learning from the statistical methods used classically.
You can find my previous article here.
Classical approach vs. machine learning
We will start by looking at how statistics is most often used in science. In most cases, with its help, we want to verify certain hypotheses that we have made beforehand (statistical inference). To do this, we use models and so-called statistical tests. They are usually embedded in certain assumptions, and in order to be able to draw legitimate conclusions, one must first make sure that these assumptions are met. I call this approach , "classical". When we try to predict the values of a trait (Y), we can use the same models, but the key will be not so much the statistical rigor (assumptions), but whether the model works -- because in business problems this is usually what we are interested in.
How do we check if a model works?
If we want to predict a trait (Y) from predictors (X), we need historical values of both (X) and (Y). We build a model, which we can then use on the new values of (X), getting an estimate of (Y). Will it be close to the truth? We don't know, because of course we don't know it. But we can apply the model on the same historical data used to build it. We will then get many estimated values of (Y), which we can compare with the true ones. If the predicted characteristic is qualitative (for example, loan repayment), we can count how many percent of the time we are wrong. If, on the other hand, we are predicting a quantitative trait (for example, the number of books sold), we can average the differences between the estimated and true values.
The above-mentioned measures, although quite intuitive, in practice are not necessarily the best for summarizing a model, and many real-world problems use others. However, this does not change the fact that we do have a way to determine how good a model is: measure how much the actual values (Y) differ from the predicted ones (and this can often be determined by a single number). What's more, when several competing models are proposed, we can choose the best one using this type of measure.
Over-fitting
In that case, don't we have to care what the model looks like, how complicated it is, or how we arrived at it, as long as the chosen measure indicates that the predicted values are close to the real ones? Yes and no.
Theoretically, since we are only interested in the result, we don't need to go into how we arrived at it. So I propose the following model: let's predict (Y) using it alone. The error of such a model is zero, but in any case it is not suitable for practical use on new data. The example is, of course, absurd, and it seems that it would never occur to anyone to approach the matter in this way. However, it turns out that many machine learning models can be made so complicated (dependent on a very large number of parameters) that they will fit perfectly on historical data and work in practice like the absurd model proposed above. We then speak of so-called overfitting(although the more popular English term is overfitting). The risk of this phenomenon is so great that special precautions should be taken: to test the model's performance on other data than those used to build it.
Training and test collection
The above recommendation is usually implemented as follows. We divide the data into two sets: the so-called training and test sets. Different ratios are used, for example, 80% and 20%. We pretend that we do not have access to the test set and build the model only on the training data. Then on the test data we check how it performs, using the measures mentioned above. This way we should not over-fit the test data (because we do not use them) and the calculated values of the measures will be reliable. It corresponds to the situation we are most interested in: whether the model will work on completely new data. Ultimately, when we choose the best method of model construction, we will use all the data to build the model.
Answering again the question of whether we don't have to worry about how the model was constructed: no, we don't, as long as it works well on the test set. Admittedly, there may still be many problems in reality, but we will discuss them in later sections.
Hyperparameters
We use the test set to evaluate how good our model is, to compare several-odd competing models. However, in the previous article, when I discussed the nearest-neighbors algorithm, we encountered the problem of choosing their number. It may just occur to the reader how this could be remedied: let's check on a test set how the model performs for a different number of neighbors, for example, 5, 10, 30. This intuition is very good. Admittedly, as we are about to explain, there is a problem with this approach, but the idea itself shows that we have assimilated the most important idea of machine learning.
But why is checking on a test set what number of neighbors to accept not necessarily the best idea? Let's start with the fact that the situation in which determining certain values is necessary to fit a model is typical in machine learning. Such values are called hyperparameters, as opposed to parameters that are set as a result of the method (in the case of the nearest-neighbor method, these are distances to individual observations). Some methods have more of these hyperparameters, making it necessary to check many combinations to determine them on the test set. In other words, we would have to ask a lot of questions of this set, which could result in over-fitting it. That is, the test set would cease to serve its function.
The solution is to separate one more set, the so-called validation set. This can be done, for example, in the proportion 60%/20%/20% (training set, validation set, test set). On this set we test different values of hyperparameters and choose the best one. We proceed in this way for different machine learning algorithms (since almost everything requires the selection of hyperparameters). On the test set we check how they work, but with already optimal hyperparameters.
This scheme also has some drawbacks, and there are popular modifications, such as the so-called crosvalidation. In contrast, some of the hyperparameters can be determined by various heuristics or intuition.

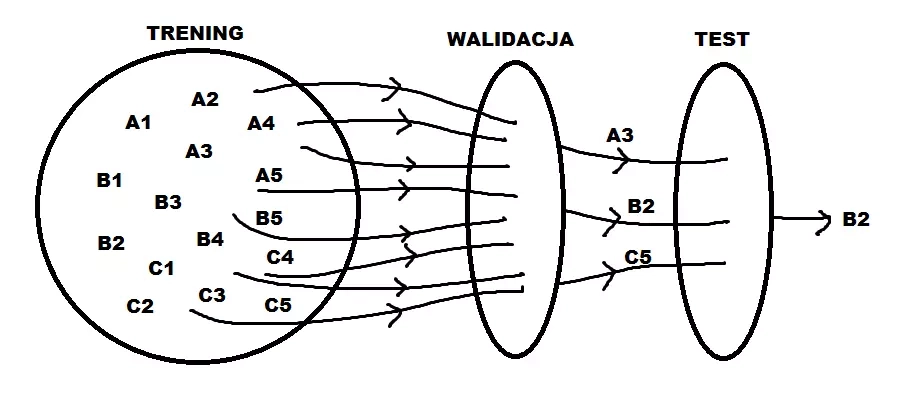
In the figure above, we consider models A, B and C, each with five hyperparameters. We build them on the training set, choose the optimal hyperparameters on the validation set, and decide on the best model on the test set.
Summary
What have we learned so far? In the first article, I gave a comprehensive overview of the model building process, distinguishing several stages. In this and the previous article, I addressed the heart of model building, that is, the mathematical description of the relationship between (Y) and (X). I found that this stage usually does not take the most time, yet I devote so much space to it because it seems the most magical. The very notion of a model can be perceived magically, but as we already know, it is simply a mathematical function that for some specific values (X1*, X2*, \ldots, X_p) returns the value of (Y). We arrive at the form of this function not on the basis of theory or intuition, but based on historical data (while hoping that the relationship under study will be the same in the past).
In order to choose the best model, we do not use all of the data, as we need some to be able to evaluate how the model performs (some somewhat ridiculously say that machine learning differs from statistics in that we divide the data into training and test data). To evaluate the model's performance, we use appropriate measures, usually determining how far the predicted value (Y) is from the actual value. What's more, we use such a measure not only to evaluate how a model performs, but also to establish hyperparameters and to select one model from many competing ones. This last statement can be considered the main idea of machine learning: since we want a model to be rarely wrong, let's simply choose the one that does so the least often. That is, there is a business purpose built into the design of the model.
In the next article, we'll explore other methods besides nearest-neighbors, the most popular in the world of machine learning today, so we should have an even better understanding of what a model really is.
Are you a manager? Do you want to become competent in using Big Data and Data Science issues? In addition, gain knowledge in the specifics of big data, integration and collection of data from various sources, and architecture of Big Data solutions? If so, be sure to check out our postgraduate program Data Science and Big Data in Management.



