



Probably every person interested in computer networks and their security has come across a buffer overflow attack. The idea of how it works is also familiar to most, but it is associated with some amazing tricks. In this article, I want to introduce how the vulnerable code looks like in detail and how you need to craft a special input string to lead to this attack.
Let's consider the simple function presented below:
void VulnFunc(char *ptr) { char buffer[32]; int i; for(i=0;(*ptr)!='&';i++) buffer[i]=*(ptr++); //further instructions acting on the buffer, not changing its //content, for example, counting the MD5 hash value from the //buffer's contents, irrelevant when it comes to the buffer overflow attack }
We can easily imagine and give the task of this function, which takes some data, copies it to the buffer and performs some operations with its help. We can easily point out the immediately apparent error: we copy the data into the buffer without checking whether we overflow it. The condition for completing the copy is encountering the & character. It is precisely such an error, as long as we can give any input data, that can be exploited.
Before we go on to prepare the appropriate string that is the exploit let's take a look at the stack during a normal function call, presented in Figure 1.

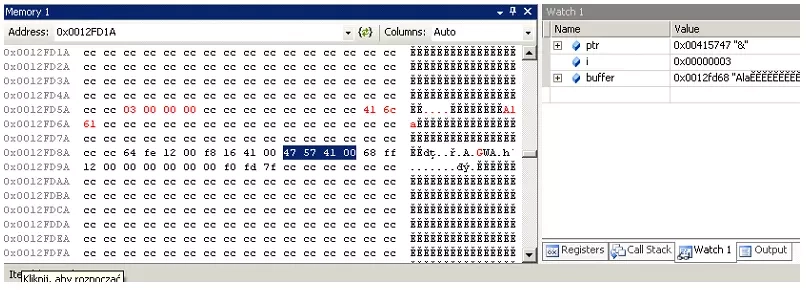
The left part of the figure shows the contents of the memory used for the stack. The areas highlighted in red are the variable i and the buffer, with the rewritten contents, in this case the text "Ala." The section highlighted in blue is the ptr pointer passed as a parameter. All this information can be confronted with the contents of the variables during the execution of the program presented on the right side of the figure.
Let's return for a moment to the address highlighted in blue, which is a parameter. In this case, our interest should be in the 32-bit address immediately before it. This address, is the return address from the function. If we manage to change it, at the time of return from function ... we will execute other code, not anticipated by the programmer.
To trace such a case, let's consider the situation when a string of the form (hexadecimal numbers) is given to the function:
0x90,0x90,0x90,0x90,0x90,0x90,0x90,0x90,0x90,0x90,0x83,0xec,0x80,0xbe, 0xe6,0x10,0x41,0x00,0x68,0x41,0x6c,0x61,0x00,0x8b,0xdc,0x6a,0x40,0x53, 0x53,0x33,0xc0,0x50,0xff,0xd6,0xff,0x15,0xe6,0x6c,0x41,0x00,0x68, 0xfd,0x12,0x00,0x26
... and, as in the previous function call, let's trace the contents of the stack.

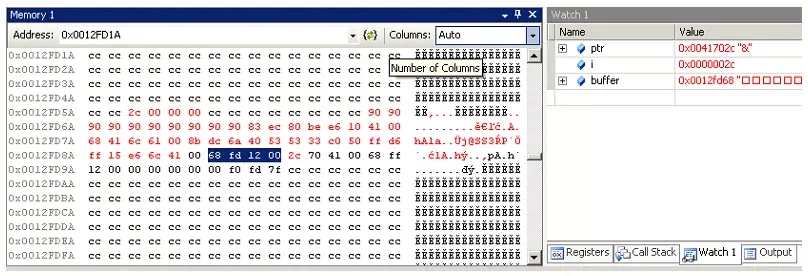
In the figure presented, we can see that much more data has been rewritten into the buffer than before. Exactly 44 bytes (hexadecimal value 2c in the memory area of the variable i). This value is larger than the buffer declared at 32 bytes. However, most importantly, or should we say, most dangerous, the return address from the function has been overwritten (the section highlighted in blue), where the instructions that will be executed by the program are now located. Remembering that variables on Intel processor machines are stored "from the end", we can decode the return address. The jump will be to the instruction located at address 0x0012fd68. If we look closely at the memory area of the stack, we can see that we will jump to the memory area presented in the figure. More precisely, the execution of the new code will start with the instruction at code 0x90. Further on, we can observe several more instructions with the same code. Such a sequence is often seen in exploits. Code 0x90 has an instruction NOP - no operation. An instruction that does nothing, but has a length of one byte. Such a sequence called NOP shove ( is useful if it turned out that we did not hit the exact beginning of the exploit code). Let's leave further analysis of this code for later ... and see what happens when we execute this code. The results are shown in the figure.

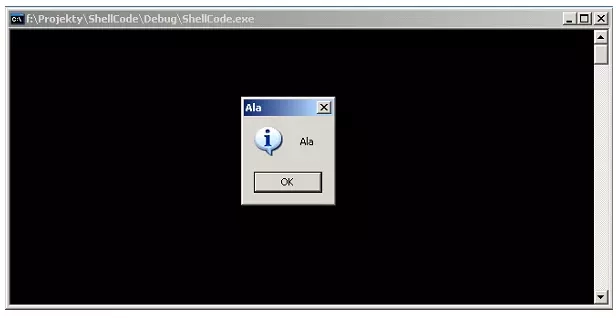
What the code does on the stack ... a little assembler
The meaning of the instruction with code 0x90 was explained earlier, now let's look at the rest of the code ... . . .
| | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
What does this code do? The first instruction subtracts 128 from the esp - stack pointer register, making room on the stack for further code. In the next, we assign the address of the MessageBox function to the esi register. Later, we set aside 5 values on the stack, first some data that we have already seen on the stack (what exactly ... I leave the reader to guess). Before we put down another 4 values we store the contents of the esp register in the ebx register. This address corresponds to the beginning of the stack, which is currently the data loaded on the stack a moment ago. In the following, we put down on the stack the number 0x40, twice the pointer pointing to some data on the stack and the value 0. Then we make a call to the MessageBoxA function. What did we do earlier on the stack? - We put down the parameters - the handle to the window (0 - NULL, i.e. a window with no connection to another window), then twice the pointer to the contents of the window and its title (do you already know what data was put on the stack? ;) ) and finally the type of the window, in our case an information window. Noteworthy is also the last value - 0x26, that is, in ASCII representation, the & character - the stop condition of the loop copying data to the buffer.
Of course, the code presented in this example does not do anything dangerous, only displays the window. However, having more space on the stack, you can plot a really dangerous function. But that's a topic for another entry ... ;)
Some explanations
The addresses used in the example exploit code were previously discovered by analyzing the code of a running program with a debugger. The architecture of Windows (well, maybe with the exception of Vista and beyond) means that in the same environment (the same installed programs) the executing program will always have the same function and stack addresses. Thus, in a test environment, they can be learned ... and used to attack other identical or similar (see the NOP sub-suite) systems. The analogy is with the address of the MessageBoxA function used.



